URLNet Learning a URL Representation with Deep Learning for Malicious URL Detection
本文最后更新于:2022年4月9日 中午
URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection
原文作者:Hung Le, Quang Pham, Doyen Sahoo, Steven C.H. Hoi
原文期刊: ACM Conference’17, July 2017, Washington, DC, USA
原文链接:https://arxiv.org/pdf/1802.03162.pdf
一、论文主要内容
我们提出了URLNet,这是一个端到端的深度学习框架,可以直接从URL学习用于恶意URL检测的非线性URL嵌入。具体来说,我们将卷积神经网络应用于URL字符串的字符和单词,以学习在联合优化框架中嵌入的URL。
这种方法允许模型捕获几种类型的语义信息,而现有模型则无法实现。我们还提出了高级词嵌入技术,以解决此任务中观察到的稀有词过多的问题。我们在大规模数据集上进行了广泛的实验,并显示出与现有方法相比可观的性能提升。我们还进行消融研究,以评估URLNet各个组件的性能。
二、作者工作
2.1 相关背景
目前已存在的钓鱼URL检测模型受到以下限制:①无法有效捕获URL字符串中的语义和顺序模式; ②需要大量的手工特征工程;③无法处理未知的特征并推广到测试集。
为了处理以上问题,本文提出了URLNet,一种基于CNN来学习URL特征以进行恶意URL检测的深度学习方法。
词法特征是将URL转换为特征向量的第一步。目前,提取该特征存在以下难点:
(i)缺少有关字符或单词在URL中出现的顺序的信息。
通过为URL 的每个段创建单独的字典,使用一些策略来利用顺序信息。例如,这可以帮助区分出现在顶级域中的“ com”和出现在URL路径中的“ com”。即使这样,此类策略也无法说明单词或字符在URL的特定段内出现的顺序。而且,这些方法无法利用可能出现在URL单词中的子字符串中的信息。
(ii)无法从稀有词中获取信息。
URL训练语料库中的许多单词仅出现一次,并且,如果使用诸如SVM的训练模型,这些功能将无法提供任何有用的信息。
(iii)无法解释测试网址中的新词。
由于新词从未出现在训练数据中,因此模型无法从这些词中提取有关URL的有用信息。
2.2 模型设计
设计思想
在URLNet中,CNN用于学习有关URL的结构信息。特别地,CNN适用于字符级和单词级。因此,在URLNet中使用多个CNN:一个用于字符级,一个用于单词级。
具体来说,URLNet接收URL字符串作为输入,并将CNN应用于URL中的字符和单词。
- 对于字符级CNN,我们首先在训练语料库中识别唯一角色,并将每个字符表示为矢量。使用此方法,可以将整个URL(一个字符序列)转换为矩阵表示形式,可以对其进行卷积。字符CNN从在一起出现的某些字符组中识别重要信息,这可能表示恶意。
- 对于单词级CNN,我们首先在训练语料库中标识由特殊字符分隔的唯一单词。使用单词嵌入矩阵,我们获得URL的矩阵表示形式(在此上下文中,它是单词序列)。可以应用此卷积。单词级CNN可以从某些单词组合中识别出有用的模式
本文贡献:
- 字符和单词CNN自动识别和学习字符和单词出现在URL中的语义和顺序模式;
- 减少了专家功能工程,因为CNN自动学习表示URL的功能,并且我们不依赖任何其他复杂或专家功能来完成学习任务;
- 该模型基于字符和单词嵌入来学习模式。
由于字符数有限,因此该字符嵌入可以轻松地推广到新的URL。对于单词嵌入,即使测试URL包含新的看不见的单词,单词的基于字符的(高级单词)嵌入仍然允许我们获得这些新单词的表示形式。
与现有方法相比,URLNet具有更好的泛化能力。
具体实现
在URLNet中使用多个CNN:一个用于字符级,一个用于单词级。
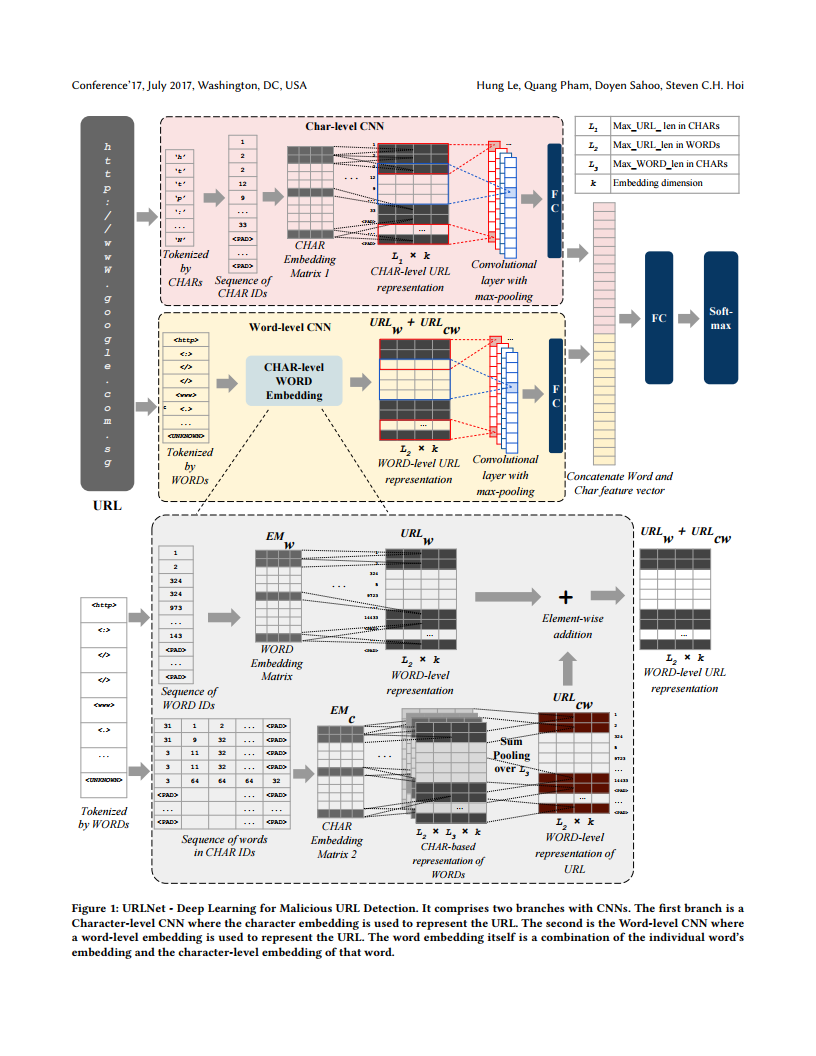
Character-level CNN
首先,我们确定数据集中所有唯一的字母数字和特殊符号。
- 字符出现次数较少的用 <UNK> 代替;
- URL长度大于 L1 = 200 的进行截断,小于的用 <PAD> 进行填充;
- 获得了 M=96 种不同字符包括 <UNK> 和 <PAD> 。
- 每个字符都嵌入到 k 维向量中。本文中,我们选择 k = 32 。
字符级的CNN还可以轻松地在测试数据中获得新URL的嵌入,因此不会遭受未知单词中提取模式的麻烦。由于字符总数是固定的,因此字符级CNN的模型大小保持不变(与基于单词的模型不同-模型大小随数据大小而增加)。
但是,字符级CNN无法利用URL中较长序列的信息。它还会忽略单词边界,从而很难区分数据中的特殊标记。此外,在恶意URL试图通过对URL的一个或几个单词进行较小修改来模仿良性URL的情况下[9],字符级CNN可能难以识别此信息。这是因为具有相似拼写的字符序列很可能从卷积过滤器获得相似的输出。
因此,还需要考虑单次级别的信息。
Word-level CNN
[1] Word-level CNNs:
所有唯一词都是由字母数字字符序列(包括“-”和“ _”)组成,并用特殊字符(例如“。”,“ /”等)分隔。
- 使用 <PAD> 令牌作为附加词,以使URL的长度在词数方面一致(L 2 = 200)。
- 将 k 设置为32,即每个单词都嵌入到32维向量中。
- 在整个训练语料库(也称为罕见词语)中所有只出现一次的单词进行了与单个 <UNK> 令牌代替。
[2] Special Characters as Words:
上边的方法没有考虑以下两种信息:
- 所用特殊字符的分布和类型;
- 特殊字符周围单词出现的时间关系。
为了解决这个问题,我们使用特殊字符作为URL字符串中的唯一单词。
[3] Using Character-level Word Embedding:
由于内存限制,以上模型未使用稀有字。此外,它无法在测试URL中获得对新单词的有效嵌入。为了解决这些问题,我们建议为每个单词获取一个字符级嵌入。
与之前从单词嵌入矩阵直接获取单词嵌入(在训练过程中了解到)的情况相反,我们将单词嵌入作为原始单词嵌入和该单词中各个字符的嵌入的组合。
接下来,我们获得URL中每个单词的 L3 × k 矩阵表示:
只出现一次的单词,在整个训练数据被忽略,并转换成一个单一的 <UNK> 令牌。
对于这些单词中的每个单词,都使用了字符级嵌入,因此即使在训练过程中,也为每个稀有单词提供了(大部分)唯一的表示形式。
以类似的方式,在测试期间,我们甚至可以为训练中未使用的新单词获得唯一的单词嵌入。其中每个单词被填充或截断为 L3 = 20 个字符的序列;
对该矩阵求和以获得单词的 1×k 矢量嵌入;
最终的URL矩阵表示形式就是两个矩阵 URL
w+ URLcw的总和。
因此,提出的字符级单词嵌入解决了基于单词的模型的存储约束问题,能够利用稀有单词的信息,还能够获得更丰富的表示形式来捕获子单词级别的信息。
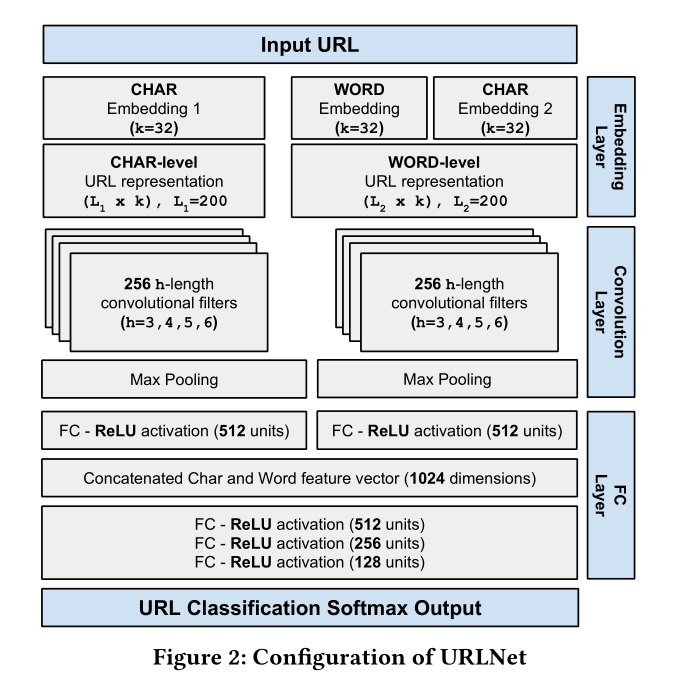
URLNet 模型参数设置
概述如图所示。
三、实验
3.1 实验数据
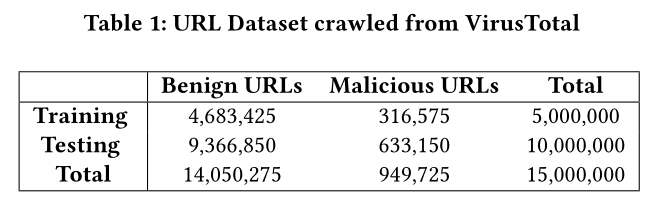
数据来自于 2017.05 - 2017.06 期间 VirusTotal 的所有URL查询链接。为了减少偏差,我们将任何URL域的频率限制为小于5%。所有未出现在任何黑名单中的URL均标记为“良性”,而所有出现在5个或更多黑名单中的URL均标记为“恶意”。由于无法确定其真实标签,所有出现在1、2、3或4个黑名单中的URL均被丢弃。从其中提取出了数以百万计的URL,其中大约94%为良性,而6%为恶意。
然后,生成的URL根据查询的时间戳进行排序。排序后,我们从前60%的URL中随机选择了500万个URL进行培训,从后40%的URL中,我们随机选择了1000万个URL进行测试。进行排序是为了避免训练模型时出现任何“前瞻性”偏差。
有关该语料库的其他详细信息,请参见表1。
3.2 实验设计
Feature Extraction
在训练模型之前,将从原始URL中提取特征。对于字符CNN,不需要特征提取,因为CNN直接在字符级别运行。对于Word CNN,我们以Bag of Words的形式提取词汇特征。
这个特征集包括:
URL Component Tokenization (UCT)
URL分为 domain ,path ,last path token 和 top level domain ,并且为每个组件构造了BoW词典。这有助于根据URL中的顺序信息捕获某些顺序。
Position Sensitive & Bigrams (PSB)
提取诸如 domain{1}和 path{2}之类的特定标记,以说明URL主域和URL路径内标记的顺序信息。这里的{x}是指距URL部分最右端的从零开始的令牌距离。
此外,还将提取 domain 和 path 中的令牌二元组,以进一步区分合法URL和恶意URL。Character Trigrams
URL域名上使用三个字符长度的滑动窗口来生成字符三联标记。这是为了处理通过修改域名的恶意URL。
通过仅提取参数名称并丢弃URL路径中的参数值,我们还执行了与[25]相同的功能处理。
除了上述的 BoW 特征,还使用了一些统计特征,将这些统计特征称为“专家特征”,因为它们是由专家手工设计的。详细特征见表2。
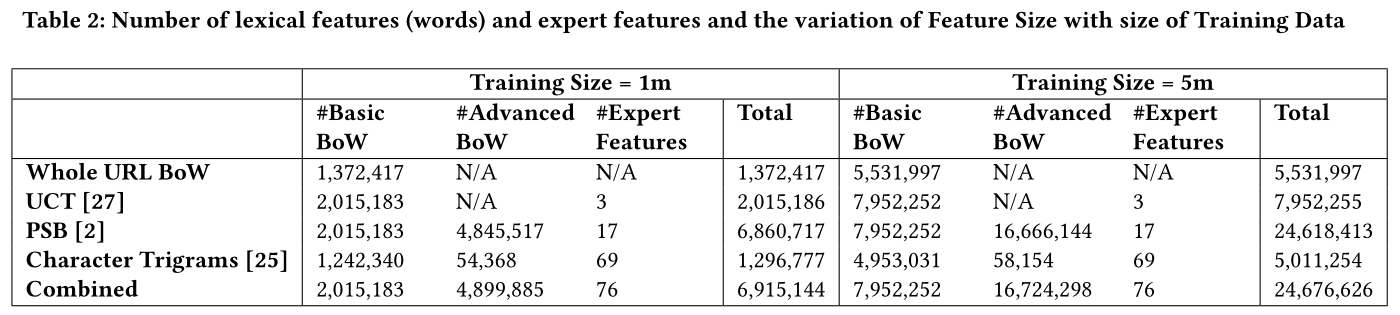
表中显示了一个具有100万个和500万个URL的语料库的单词或特征数量。基本BoW是指通过传统BoW方法获得的特征。高级BoW指的是诸如bigram和(字符)trigram特征之类的特征。
可以看出,词汇特征的总数可能非常大,并且会随着数据大小的增加而不断增加。相应地,基于单词的模型的大小也在不断增加。
Word-frequency Distribution
我们获得了100万个URL的整体URL BoW特征,根据整个训练数据中单词出现的频率绘制了单词的百分比。见图3。
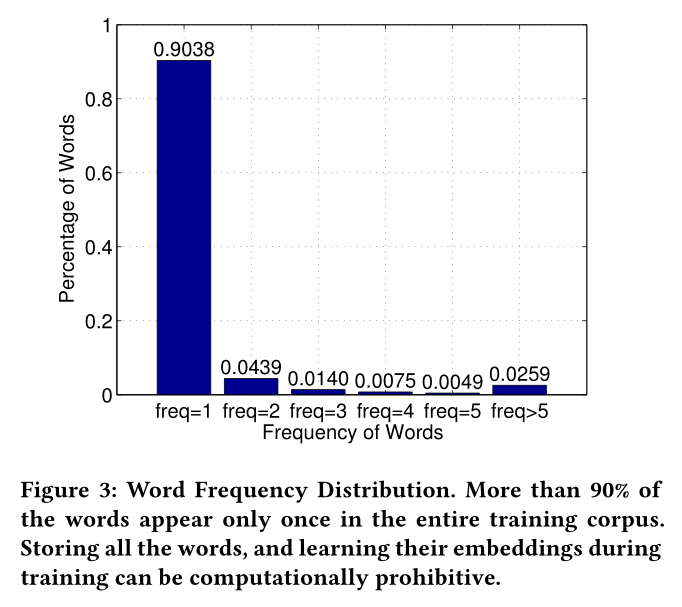
可以看出,训练语料库中90%的单词仅出现一次。这意味着URL训练语料库中90%以上的独特词非常稀有。尽管稀有词在字典中占多数,但存储它们需要大量内存,并且不适用于大型数据集。
通过忽略稀有单词,我们能够解决内存问题,并有可能在大型数据集上训练与单词相关的模型。此外,我们提出的字符级单词嵌入功能使我们甚至可以获取稀有单词的表示形式(不存储这些单词的嵌入内容),并且还可以捕获每个单词的本地子单词信息。
3.3 实验结果
Evaluation of URLNet
作为基准模型,我们使用了L1正规化的L2损失SVM(在Liblinear [11]中实现)。根据[2,25,27],对SVM进行了上一节中介绍的5组基准词汇特征的训练。
基准方法包括在以下方面训练的SVM:
- 整个URL BoW;
- UCT [27];
- PSB [2];
- Character Trigrams[25];
- 结合:所有这些特征的结合。
我们将基准与提出的URLNet进行了比较:
- URLNet(Character-Level)
- URLNet(Simple Word-Level)
- URLNet(Full)
该实验的主要结果可以在表3中看到,在图4中进一步可视化AUC特性。

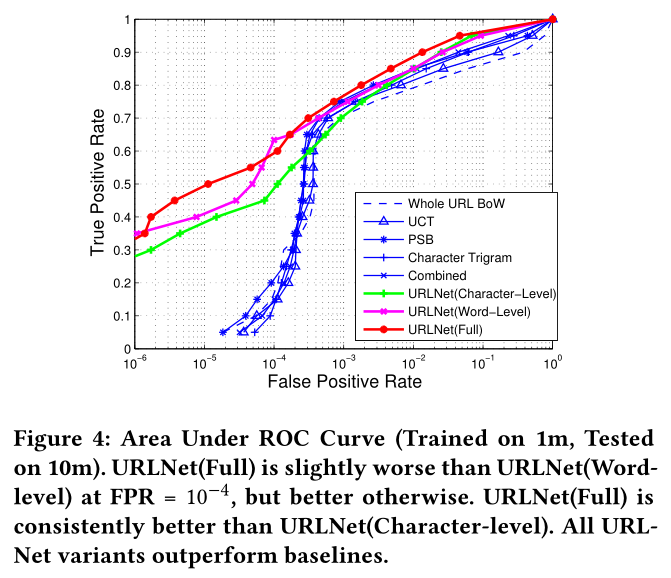
一般而言,基于URLNet的方法在所有指标(AUC和TPR @ FPR)上均明显优于基线方法。在基准模型中,我们观察到,通过使用URL组件标记化(UCT)中的单独词典来启发式地计算顺序信息,可以比使用简单的整个URL BoW特征提高性能。同样,使用其他高级特征和专家特征(PSB和Character Trigrams)也可以提供渐进的改进,并且通过将所有特征组合在一起可以获得最佳的基准模型。
相反,在不使用任何专家或手工设计的特征的情况下,URLNet方法可使AUC大大超过基准。显然,所提出的URLNet能够捕获URL中的几种语义和结构信息,而基于词袋特征的现有方法则不能。
在URLNet中,我们观察了三种变体的性能:字符级,单词级和完整级。字符级和单词级URLNet具有相似的性能,而URLNet(Full)在很大程度上利用了两者的优点,并提供了更加一致的更好性能。 FPR较低时,字级URLNet的性能优于字符级URLNet,而FPR较高时,则相反。 URLNet(Full)结合了两者的优点,除了FPR = 0.0001以外,它在所有其他情况下都提供了更好的性能,包括显着提升了AUC。
总体而言,我们还观察到训练数据大小从100万增加到500万对所有指标都有积极影响。
Ablation Analysis
URLNet的不同组件的性能以及每个组件的性能提升可在表4中看到。
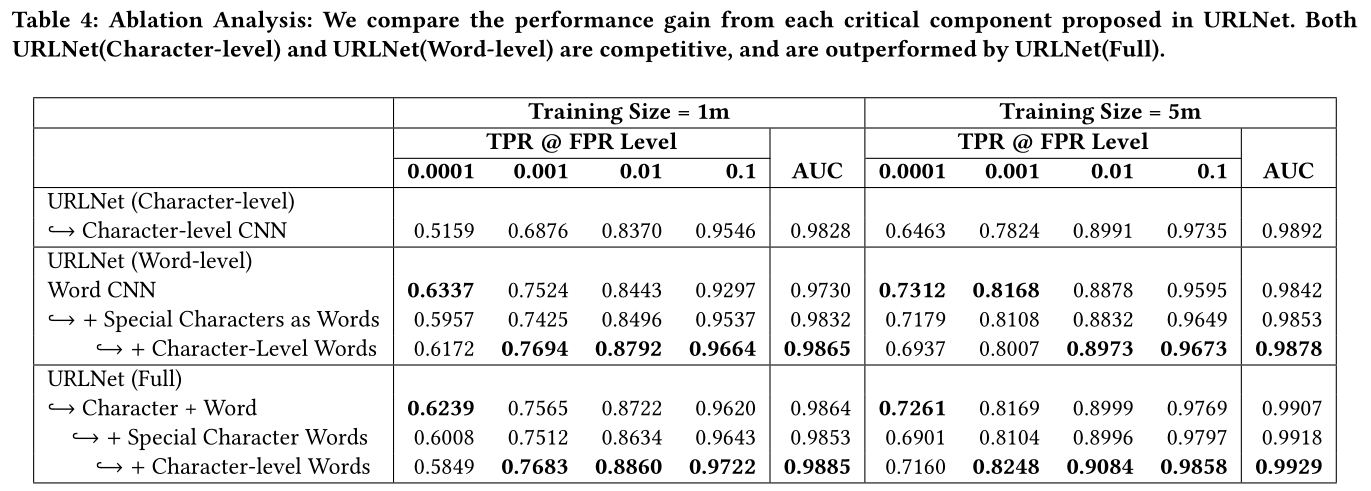
在URLNet(单词级)中,将特殊字符视为单词并使用字符级单词嵌入可提高AUC得分。这验证了特殊字符作为单词的用法以及字符级单词嵌入的好处。即使此改进与变化的训练数据大小一致,但在FPR较低的级别上仍会出现微小差异,其中简单单词级别的URLNet提供最高的TPR。
可能的原因是,使用特殊字符作为单词,并使用字符级单词嵌入使单词级CNN的性能与字符级CNN的性能略有相似,这就是为什么在高FPR时性能会提高,而在FPR低,这会使情况恶化。
单词级URLNet的趋势一直延续到URLNet(Full),在这里,随着我们一次集成一个附加特征(特殊字符(如单词和字符级单词)),我们看到了AUC的稳步改善。
总体而言,URLNet(Full)利用字符级和单词级信息,并且大大优于基于字符的URLNet和基于单词的URLNet。
Visualization
略。。。
四、结论
在本文中,我们提出了URLNet,一种基于CNN的深度神经网络,用于恶意URL检测。现有方法大多使用词袋之类的功能,这使它们遭受一些关键限制,包括无法检测URL字符串中的顺序概念,需要手动进行特征工程以及无法处理测试URL中看不见的特征。
为此,我们提出了字符CNN和单词 CNN,并共同优化了网络。此外,我们提出了先进的词嵌入技术,这些技术对于处理稀有词特别有用,这通常是在恶意URL检测任务(而不是传统的NLP任务)中发现的问题。这种方法还允许URLNet在测试时从看不见的单词中学习嵌入,并利用子单词信息。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!