Cracking Classifiers for Evasion A Case Study on the Google’s Phishing Pages Filter
本文最后更新于:2022年4月9日 中午
Cracking Classifiers for Evasion: A Case Study on the Google’s Phishing Pages Filter
原文作者:Bin Liang, Miaoqiang Su, Wei You, Wenchang Shi, Gang Yang
原文期刊:WWW ‘16: Proceedings of the 25th International Conference on World Wide Web April 2016 Pages 345–356
原文链接:https://dl.acm.org/doi/10.1145/2872427.2883060
一、论文主要内容
在本文中,我们使用Google的钓鱼网页过滤器(GPPF)来调查客户端分类器面临的安全挑战。
我们针对客户端分类器提出了一种新的攻击方法,称为分类器破解。通过该方法,我们成功破解了GPPF的分类模型,并提取了可用于逃避攻击的足够知识,包括分类算法,评分规则和特征等。最重要的是,我们完全逆向工程了84.8%评分规则,涵盖了大部分高加权规则。
根据破解的信息,我们对GPPF进行了两种规避攻击,即插入好特征和消除坏特征,使用100个真实的网络钓鱼页面进行评估。实验表明,可以轻松地操纵所有网络钓鱼页面(100%)以绕过GPPF的检测。我们的研究表明,现有的客户端分类器非常容易受到分类器破解攻击的攻击。
二、作者工作
2.1 相关背景
机器学习已经被广泛应用于安全领域,各种分类器用于检测恶意网页,垃圾邮件,网络钓鱼,恶意软件等。不足为奇的是,分类器本身也已成为攻击者的攻击目标。
根据针对分类器的攻击分类,攻击对分类器的影响可分为两类:
(1)因果攻击,会干扰训练过程,从而控制训练数据以降低分类器的性能,
(2)探索性攻击,利用受过训练的分类器的知识来导致错误分类,而不会影响训练过程。
但是,现有研究常常忽略了一个重要事实,即某些分类器部署在完全由用户控制的客户端环境中(简称客户端分类器),而不是在远程服务器中。在这种情况下,分类器面临更严重的安全性挑战。因此,应仔细研究对手如何从部署在用户客户端中的分类器中学习可利用的知识,以及如何有效地利用知识来发起逃避攻击。
2.2 模型设计
设计思想
我们通过对Google网络钓鱼页面过滤器(GPPF)进行案例研究来调查客户端分类器的安全挑战。分类器集成在Chrome浏览器中,并被用户访问的每个网页调用,以检查其是否为网络钓鱼。由于Chrome的普及,它也可能是使用最广泛的分类器。如果对手可以轻松地逃避它,那么无数用户将受到不受控制的网络钓鱼攻击。
在本文中,我们演示了一种实用有效的攻击方法,称为分类器破解,其中利用了各种逆向工程技术从客户端分类器中提取足够的知识来发起逃避攻击。根据破解的信息,我们设计了两种规避攻击的方法,即插入好特征和消除坏特征。
本文贡献:
- 针对客户端分类器,提出了一种新的攻击方法,即分类器破解。攻击者可以跟随它从目标分类器中轻松获取可利用的知识,以发起有效的逃避攻击。
- 成功破解并逃避了GPPF。它证明了现有的客户端分类器确实容易受到分类器破解攻击的攻击。
具体实现
首先,分类器按照URL,DOM和Term功能的顺序从当前网页中提取三种页面功能。
其次,使用SHA-256算法对收集的页面特征进行哈希处理,并将其与哈希模型特征一起发送到函数ComputeRuleScore() 以计算每个评分规则的规则得分。
第三,ComputeScore() 组合所有规则得分以生成当前页面的最终得分。
最后,将分数与预定义的阈值(固定为0.5)进行比较。如果分数小于阈值,则该页面将被识别为合法;否则,它将被视为潜在的网络钓鱼页面。
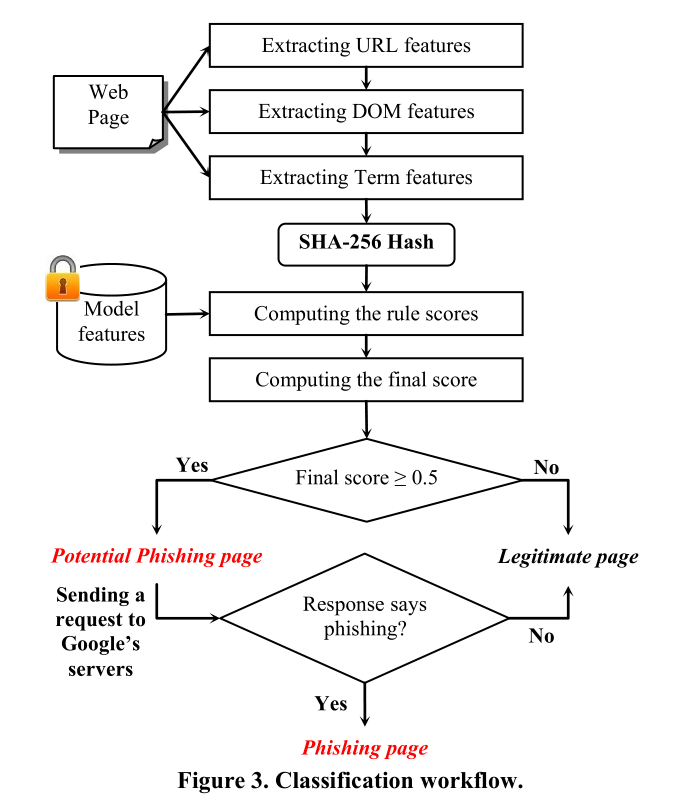
在计算分数时,三种页面特征将以不同的方式映射到相应的模型特征中。
URL features

DOM features

Term features
在GPPF中,页面中出现的术语被视为一种功能。术语功能可以是单个单词,也可以是多个单词的组合(最多五个)。 GPPF使用一个名为 previous_words 的数组来构造页面术语特征。
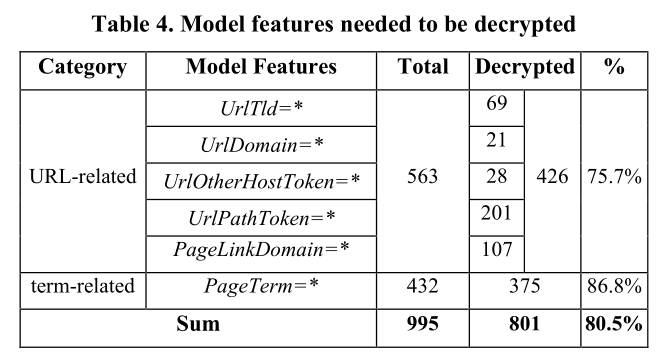
如表4所示,我们通过碰撞攻击成功解密了801(80.5%)个模型特征。连同在模型提取中恢复的14个特征,我们最终获得了总共815个(80.8%)模型特征的完整明文。
三、实验
我们设计了两种规避攻击,即插入好特征和消除坏特征。它们背后的基本思想是在网上钓鱼页面中添加或删除适当的好或坏特征,以使其网上诱骗分数低于阈值,从而导致分类错误。
数据集:从PhishTank收集的100个真实钓鱼网页
Good Features Insertion
我们只能对所有带有一个恢复特征的负规则按其权重进行排序,并直接将权重最高的规则的特征用作所有目标页面的良好候选特征。
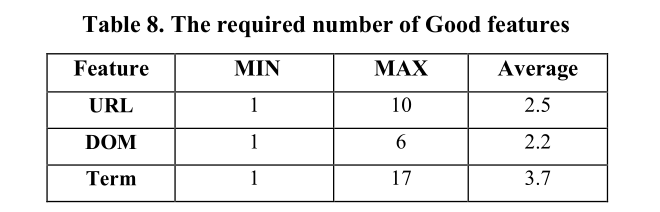
对于数据集中的许多网络钓鱼页面,我们只需插入一个如此好的功能就可以轻松将其转换为合法页面。而且,如表8所示,我们发现仅使用一种优良功能也是有效的。例如,通过在页面中插入最多六个良好的DOM功能,我们可以将所有测试页面的得分降低到低于0.5。平均而言,需要2.2个良好的DOM功能。
Bad Features Elimination
我们设计了一种基于搜索的方法,可以自动为给定页面选择适当的不良功能。具体来说,我们实现了一个脚本,通过从页面中删除一个要素或一组要素并重新计算分数,来计算一个要素或一组要素对最终分数的贡献。
对于给定的页面,我们将该脚本应用于其所有恢复的特征。在删除功能或特征集之后,页面的分数将变得低于阈值,从而可以将其分类为合法页面。
在实验中,我们发现删除最多五个不良特征足以使页面逃避分类器。平均而言,需要3.1个不良的DOM特征。
四、结论
在本文中,我们提出了一种新的攻击方法,即分类器破解,用于逃避客户端分类器。我们利用各种逆向工程技术从客户端分类器中直接提取所需的知识,以发起逃避攻击。
我们的研究以GPPF为例进行研究,这是一种基于学习的网络钓鱼网页过滤器,拥有超过10亿用户。利用各种逆向工程技术,我们成功破解了GPPF模型,并完全恢复了84.8%的加密评分规则。
根据这些信息,我们开发了两种规避攻击:插入好特征和消除坏特征。攻击实验表明,我们可以轻松操纵所有网络钓鱼页面(100%),以使它们成功逃脱最新版本Chrome中对GPPF的检测。
另外,我们分析了可以潜在地应用于客户端分类器的保护方法,但是遗憾地发现,使用本技术很难彻底防止客户端分类器被破解。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!