Adversarial Sampling Attacks Against Phishing Detection
本文最后更新于:2022年4月9日 中午
Adversarial Sampling Attacks Against Phishing Detection
原文作者:Shirazi, Hossein Bezawada, Bruhadeshwar Ray, Indrakshi Anderson, Charles
原文期刊:International Federation for Information Processing 2019
原文链接:[https://doi.org/10.1007/978-3-030-22479-0_5](https://doi.org/10.1007/978-3-030-22479-0_ 5)
一、论文主要内容
作者提出了一种直接修改特征来生成对抗抗本的方法,以此来模拟攻击检测器。实验显示,通过修改一个特征就可以使钓鱼网站的识别率降低到 70%,修改4个特征可以使所有对抗样本骗过检测器。意味着,任何一个本来可以被分类器模型正确检测到的钓鱼样本,最多可以通过改变四个特征值来绕过分类器。我们为每个数据集定义了脆弱性水平的概念,它衡量了可以被操纵的特征数量和操纵的成本。
二、作者工作
2.1 相关背景
在现有的基于机器学习的网络钓鱼检测方法中,一个关键的假设是,训练数据收集过程独立于攻击者的行为。然而,在对抗性情境中,例如网络钓鱼或垃圾邮件过滤,这与现实情况相去甚远,因为攻击者要么产生噪声数据样本,要么通过操纵现有样本的特征产生新的攻击样本。嘈杂的数据样本导致分类模型的准确率很低,操纵特征的结果是一种比较危险的情况,攻击者会在这种情况下 可以不费吹灰之力地绕过现有的分类器。在这项工作中,我们探索并研究对抗性抽样对网络钓鱼检测算法的影响。
2.2 方法及贡献
我们收集了其他研究人员开发的四个独立的公开数据集,并应用对抗性抽样技术来评估训练模型对人工生成的对抗性样本的鲁棒性。 我们展示了当前检测方法的脆弱性,并探讨了数据集对特征工程以及学习模型的鲁棒性。
本文贡献:
我们针对当前的防御和检测机制建立了威胁模型,并解释了攻击者的访问和知识,攻击者利用这些知识来攻击任何给定的训练好的分类器模型。
我们定义了钓鱼实例的脆弱性水平,量化了攻击者的努力,并描述了一种操纵钓鱼实例和创建新样本的方法。
我们调查了全方位的网络钓鱼检测技术,重点是基于机器学习的方法。我们展示了一些著名的机器学习方法的弱点,并强调了网络钓鱼者如何能做到这一点。生成新的钓鱼网站实例,以规避每个钓鱼网站的训练分类器。
我们建立了一个实验,并进行了广泛的实验。并针对对抗性样本测试分析了数据集和学习模型的脆弱性。
威胁模型
我们从一般机器学习解决方案中攻击者的目标、知识和影响力入手,然后结合网络钓鱼问题进行解释。我们根据攻击者的能力,对现有钓鱼实例的对抗性样本生成进行建模。然后评估对手为成功执行这种攻击所要付出的成本。
攻击者的目标
在网络钓鱼的情况下,对手会攻击系统的完整性。攻击者希望攻击的是特异性的学习模型,这会导致对抗性的分类不正确。攻击特异性取决于攻击者是想对一组特定的样本(如网络钓鱼)还是任何给定的样本进行错误分类。错误特异性与攻击者努力增加系统中特定类型的错误并降低其他分类器分数有关。另外,在错误特异性方面,攻击者希望降低真阳性率(TPR)。
攻击者的知识 (白盒 / 黑盒 / 灰盒攻击)
从数据集的角度来看,攻击者可能部分或全部获得训练数据集。攻击者也可能对特征表示或特征选择算法及其标准有部分或全部的了解。在最坏的情况下,攻击者可能知道所选特征的子集。在我们的研究中,我们假设对手的知识有限。对手知道分类器模型和特征集,但不知道训练集、分类器或分类器的训练参数。
攻击者的影响
主要有两种攻击类型:数据投毒和逃避攻击。
在这项工作中,我们假设攻击者对学习模型的了解是有限的,但对学习模型的预测函数没有访问权。攻击者可以根据需要测试任意多的实例并得到结果。在这种假设下,攻击者可以创建大量的新样本,并对分类器进行测试,看看他们是否可以绕过模型。
三、对抗样本
我们模拟攻击者的方法,根据分类器检测到的现有钓鱼实例生成新的对抗样本。攻击者根据这些现有的钓鱼实例生成新的实例,以检查生成的实例是否能够躲过分类器。我们假设攻击者对URL和网页内容有完全的控制权,除了域名是唯一的。
选择用于修改的特征

攻击成本
攻击者以某种方式改变网站,使其产生类似于对抗性样本的所需向量。这不是一个琐碎的过程,它对攻击者来说有相当大的成本。而对抗性样本可能有更高的机会躲过分类器,但它们可能在视觉上或特征上与目标网站不相似。这就增加了被终端用户检测到的机会。因此,对手希望最小化两个参数:修改特征的数量和分配的特征值。我们将其作为攻击者的成本函数。
$$ {欧几里得距离}
d(x_i,x_i^i)=\sqrt{\sum_{k=1}^n (x_i^k-x_i’^k)^2}
$$
$l$ 为操纵特征的数目,从而使 $x_i\to x_i’$ ,$d$ 为两者之间的欧氏距离,$c$ 为成本。
$$
C(x_i,x_i’)=(l,d)
$$
脆弱等级
一个已经被正确预测的钓鱼实例,如果通过操纵$l$个特征和距离$d$,它可以绕过分类器,我们称这个实例为脆弱的。这里攻击者的目标是优化$l$和$d$ 。
例如:有一个钓鱼实例,已经被分类器检测到了,但是有通过操纵3个特征生成的新实例,并且欧氏距离为2.7绕过了分类器,则原样本在3级时易受攻击,成本为2.7。
四、实验
Exp-1: Evaluation of Datasets
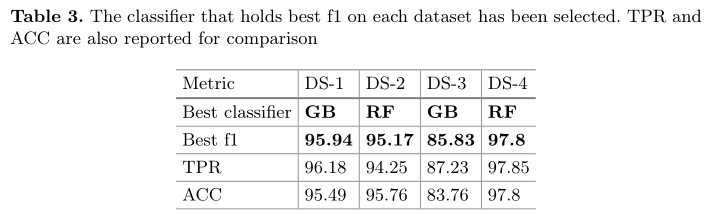
Generating Adversarial Samples
在每个数据集中,我们保留了200个钓鱼实例,然后在没有保留200个钓鱼实例的情况下训练模型。生成的对抗性样本需要与钓鱼实例相似且有效,否则,这些不能被假定为钓鱼实例。
要给特征分配新的值,生成新的实例。我们只是使用以前在钓鱼实例中看到的值。通过这种策略,可以保证新分配的值是有效的,并且已经在数据集中的其他钓鱼实例中看到过。
我们随机选择特征的组合,最多四个不同的特征,并改变每个特征的值与所有可能的特征值。
在创建每个新样本后,我们根据所选的分类器测试我们的新样本,并检查它是否可以绕过分类器。如果可以,我们认为原始钓鱼实例是一个脆弱的实例。我们计算新实例和原始实例之间的距离,以找到最接近的可以绕过分类器的实例。
Exp-2: Robustness of Learning Model
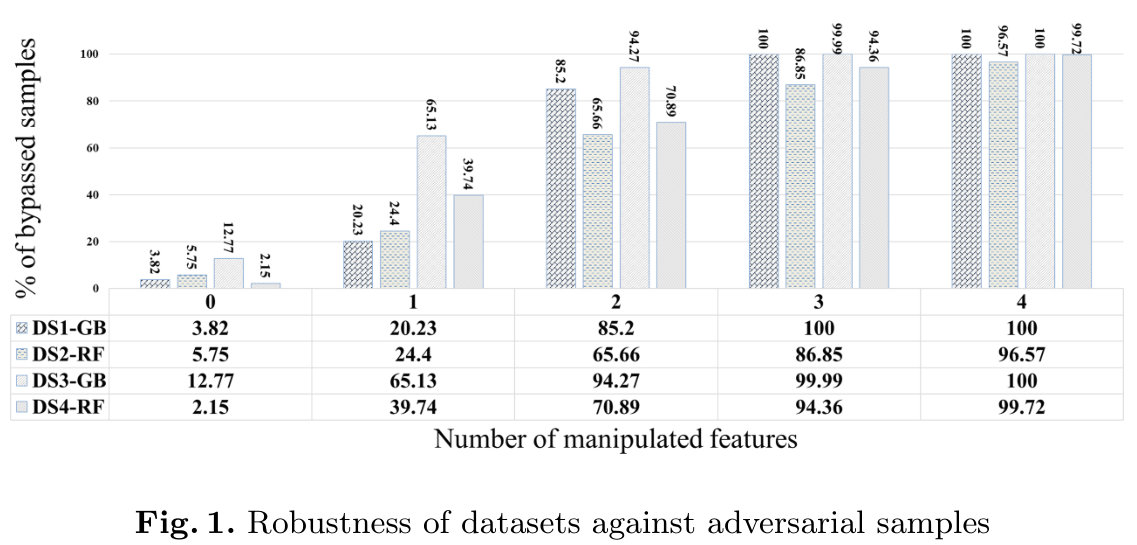
图1显示了Exp-2的结果。X轴显示的是操纵特征的数量,零操纵特征意味着测试发生在原始钓鱼实例上,没有任何扰动。 结果的趋势显示,通过增加扰动次数,被逃避的样本数量按比例增加。
我们继续增加扰动特征,每次最多增加四个不同的特征。我们观察到,在四个特征的情况下,几乎所有的钓鱼实例都会绕过分类器模型。
Exp-3: Dataset Vulnerability Level
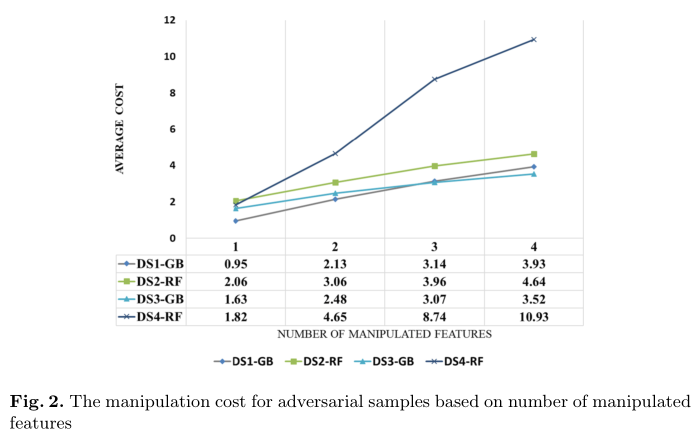
图2给出了针对两个参数的所有数据集的实验结果:操纵特征的数量和对抗实例的平均成本。显然,通过增加操纵特征的数量,成本也稳定增加。
例如,对于数据集DS-1,具有一个操纵特征的对抗性样本的平均成本为0.95,而具有四个操纵特征的平均成本为3.93。
此外,很明显,某些数据集的平均成本高于其他数据集。 例如,在DS-4中,对手必须支付更多费用,尤其是当要素数量与其他数据集相比增加到三个和四个时。 这表明该数据集对这些攻击更具鲁棒性,并且漏洞级别较低。 同样,很明显,通过以较小的成本进行单个特征操作,就可以绕过分类器。 设计数据集和要素时需要考虑这一点。
五、结论
在这项工作中,我们解释了当考虑到对抗性样本时机器学习技术的局限性。我们引入了基于对抗性攻击的数据实例和数据集的脆弱性水平概念,并对其进行了量化。在没有这种攻击的情况下,我们使用七种不同的文献中研究得很好的分类器取得了很高的准确率:除了一种分类器的准确率为82%外,其他分类器的准确率都超过了95%。然而,当我们针对对抗性样本评估表现最好的分类器时,该分类器的性能明显下降。在只有一个特征扰动的情况下,TPR从82-97%下降到79%-45%,并且,将扰动特征的数量增加到4个,TPR下降到0%,这意味着所有的钓鱼实例都能够绕过分类器。
我们继续进行实验,在实验中考虑对手成本。我们表明,操纵特征的数量和总的操纵成本都是至关重要的,而总的操纵成本可以从原始钓鱼样本和对手样本的差异中得出。这意味着,从攻击者的角度来看,不仅希望改变最小的实例数量,而且对手样本具有最小的成本也很重要。这是一个令人印象深刻的结果,并显示了知名的防御机制对钓鱼攻击的弱点。在未来,我们希望设计出对对抗性学习攻击免疫的鲁棒机器学习模型。
Todo
- 各个数据集的特征各不相同,如何选取最大收益的特征,有些特征不应当修改
- 两个样本之间的向量欧式距离?
- 修改后的样本长什么样?
- 刻意设计的数据集对训练模型的意义?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!