Phishing URL Detection with Oversampling based on Text Generative Adversarial Networks
本文最后更新于:2022年4月9日 中午
Phishing URL Detection with Oversampling based on Text Generative Adversarial Networks
原文作者:A. Anand, K. Gorde, J. R. Antony Moniz, N. Park, T. Chakraborty and B. Chu
原文期刊:2018 IEEE International Conference on Big Data (Big Data)
原文链接:10.1109/BigData.2018.8622547
一、论文主要内容
在二元分类任务中经常出现不平衡类的问题。如果一个类的数量超过了另一个类,训练好的分类器就会严重偏向多数类。对于钓鱼网址检测,收集到的良性网址(即多数类)的数量远远大于收集到的虚假网址(即少数类)的数量。对少数类别进行过采样是克服这种情况的有力工具。然而,现有的方法是在特征空间中执行过采样任务,在特征空间中,原始数据格式被删除,URLs被简洁地用向量表示。这些方法只有在特征定义正确且数据集多样且不太稀疏的情况下才会成功。
在本文中,我们提出了一种数据空间的超采样技术。我们用少数类的URLs训练文本生成对抗网络(text-GANs),并生成可以成为训练集一部分的合成URLs。我们抓取URL资源库来收集最近发现的虚假和良性URL。我们的实验表明,在使用所提出的超采样技术后,性能有了显著的提高。有趣的是,一些原始的测试URL是由所提出的文本生成模型精确地重新生成的。
二、作者工作
2.1 相关背景
先前的工作表明,使用机器学习来检测此类网络钓鱼URL很有希望。但是,该域存在一个重要的内在问题:数据集不平衡。实际上,良性URL的数量超过了虚假URL的数量。
通常,这种情况通常通过对少数类进行过采样来解决。现有的特征空间过采样方法通过以下步骤来创建类似于真实样本的合成样本:
i)将数据样本转换为特征空间的向量,ii)查找现有向量的随机加权组合。
2.2 模型设计
设计思想
我们提出的过采样技术和GAN模型。上面讨论的类不平衡问题可以通过以下方式解决:
- 在我们的数据集中使用少数类训练GAN模型。
- 训练好的GAN模型用于生成多个URL。
- 通过代表性的选择方法选择由高质量生成的URL组成的子集,并将该子集用于增强数据集的少数类。
- 如果在步骤3之后获得的代表数量不足,则运行现有的特征空间过采样算法以实现两个类别之间的平衡。
- 使用现已完全平衡的数据集,训练了最新的分类算法来预测网络钓鱼URL。
通常,步骤1中的GAN模型会生成大量的候选URL。这些URL都不能直接用来增强少数派类,因为这又一次造成了反向不平衡的局面。我们要精心选择一个代表步骤2中生成的URL的子集。
将选定的代表添加到少数类后,如果生成的代表数量太少而无法解决不平衡问题,则在特征空间中执行现有的过采样方法以实现完美的平衡。我们的实验表明,基于文本GAN和现有特征空间过采样的代表性选择的建议组合显着提高了预测准确性。
现有的特征空间过采样方法仅产生现有矢量的加权组合。基于文本GAN生成的样本比仅依赖现有特征空间过采样方法的样本更具多样性。
具体实现
A.文本生成对抗网络(text-GAN)
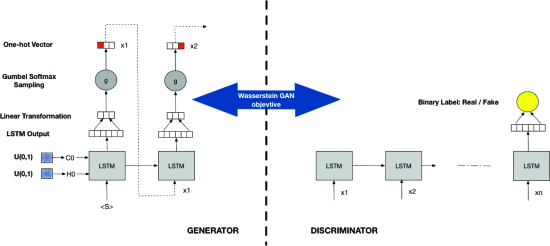
用于生成文本的GAN比用于图像的GAN更难训练[25]。因此,我们采用了两种最近提出的技术:采用了Wasserstein度量[2]和Gumbel Softmax [14]。图1显示了本文中使用的GAN架构的示意图。
- Wasserstein Objective
Wasserstein度量标准按以下方式测量两个概率分布之间的距离:
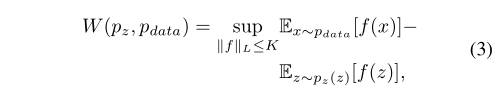
其中上位数为所有K-Lipschitz函数的上位数。[2]指出,神经网络能够在每次梯度更新后将其权重箝制在一个固定的区间,从而大致逼近这样的K-Lipschitz函数。
为了提高GAN训练过程的稳定性,我们采用Wasserstein GAN训练目标。我们还并入了一个梯度罚分项,该函数消除了原始Wasserstein GAN实施中由于权重裁剪而引起的不良行为[10]。
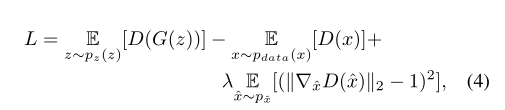
其中,$\hat x$ 代表数据分布和生成器分布之间的直线,λ是一个超参数,它控制优化惩罚项和原Wasserstein目标之间的权衡。
- Recurrent Architecture
我们模型中的生成器和鉴别器都是LSTM [13]。生成器生成一个字符一个序列的字符,其中每个字符通过单次热编码表示。生成器的单元状态和隐藏状态由从z〜U(0,1)d采样的一对向量初始化。
在LSTM的每个时间步长上,LSTM输出都通过线性层,然后是Gumbel-Softmax层。Gumbel-Softmax层从Gumbel-Softmax分布中采样并产生离散输出。然后将在给定时间步生成的字符输入到LSTM中,作为下一个时间步的输入。
Gumbel-Softmax Distribution
Gumbel-Softmax分布可以被用来训练离散潜变量的神经网络。具体来说,Gumbel-Softmax技巧提供了一种有效的方法,从分类分布中抽取样本z,其类概率为 $\pi_i$ 。
$$
z=onehot(argmax[g_i+log{\pi_i}])
$$
其中,$g_i$ 是从均值为零、单位方差的Gumbel分布中抽取的i.i.d样本。由于argmax函数是不可微分的,我们简单地使用softmax函数作为argmax的连续近似。
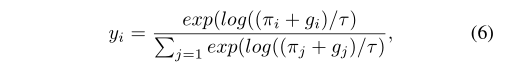
其中τ是一个温度参数,允许我们控制Gumbel-Softmax分布的样本与分类分布的样本的接近程度。当τ → 0时,softmax变成argmax,Gumbel-Softmax分布变成分类分布。在训练过程中,我们让τ>0,以允许梯度经过样本,然后逐渐退火温度τ(尽管不是完全退火到0,因为梯度随后会爆炸)。
B. Representative Selection
在许多生成的URL中,我们选择一小部分具有代表性的URL作为训练集的一部分。在我们的实验中,我们生成了数百万个URL,并平均选择了数千个代表性URL。
- k-Means Clustering
每个生成的URL都投影到特征空间上,我们在其中运行k -Means聚类算法以找到k个质心(即代表)。该方法的关键部分是参数k的选择。为此,我们使用了一种称为剪影得分[21]的无监督指标。轮廓分数可计算不带有真实标签的群集的一致性。将相似的URL分配给群集后,其轮廓分数就会增加。
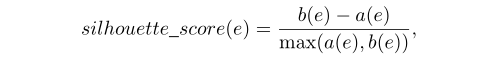
其中e是生成的URL样本,a(e)是e与它所属的群集的其他URL之间的平均距离,而b(e)是e与它不属于的群集的其他URL之间的最小平均距离。
一般来说,k的大小不足以匹配两个类的大小。因此,我们在选择k个有代表性的生成URL后,运行特征空间超采样算法来完全匹配大小。由于额外的k个URL样本,特征空间超采样与没有这些样本的情况下执行时表现出非常不同的行为。请注意,由 不对k个URL进行特征空间过采样(如图所示)图3(b))的多样性不如当 包括k个URL(如图3(d)所示)。
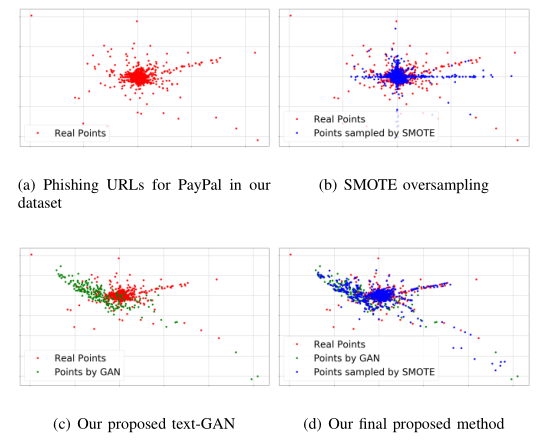
图3:二维空间中的真实和合成URL。我们使用 Hessian Eiggenmapping [7],一种维度减少算法,将 URL 投射到二维空间中。
(a)我们数据集中PayPal的钓鱼网址。
(b)蓝色点代表由SMOTE合成的样本。
(c)绿色点是由提出的GAN经过基于欧氏距离的代表选择(α=0.5)后得到的;注意绿色点与红色点的分布不同,因为代表选择方法更倾向于欧氏距离最远的样本;在维度降低后,它们在某种程度上是重叠的。
(d)我们在(c)上应用SMOTE得到增强的少数派类(由三种颜色的点组成)。(d)之后,两个类的大小相同。
- Euclidean Distance
在特征空间中,我们首先找到少数类的中心点(即均值向量),然后选择k个与中心点的欧氏距离最大的生成URL。因此,这种欧氏距离法优先选择与少数类中存在的样本不同的样本。有时,由于选择的URL的多样性增加,这样产生的预测结果比k-Means聚类法更好。
在这种方法中,我们设置$ k = α·(|Majority|−|Minority|)$(例如,当α = 0.5时,k是所选URL的数量将是类大小差异的一半)。为了解决剩余的不平衡问题,我们像前面的k -Means聚类方法一样对特征空间进行过采样,并使两个类的大小相等。
- Random Selection
我们选择$ k = α·(|Majority|−|Minority|)$随机生成URL。经过测试,该方法表明需要有原则的代表性选择方法。
C. Generated URL Examples

三、实验
3.1 实验数据
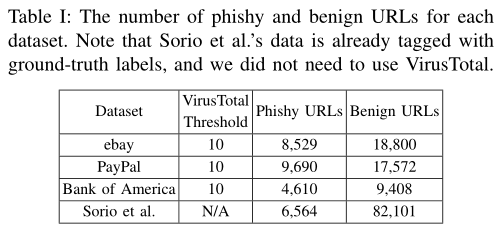
我们对phishtank.com进行了爬网,并收集了最近六个月针对美国银行,eBay和PayPal报告的URL。我们使用virustotal.com标记了收集的URL。在其中选择了10种最可靠和最受欢迎的产品,并且如果所有检测都表明是phish URL,则认为该URL是phishy。表I显示了数据集的统计信息。
3.2 实验设计
包含80%的钓鱼URL和良性URL的随机选择子集用于训练,其余20%保留用于测试。对于训练,我们执行网格搜索和10倍交叉验证,以选择最佳的超参数集。我们考虑了DecisionTree,AdaBoost,RandomForest,SVM,RBM,多层感知器等。对于特征空间过采样,我们考虑了相关工作部分中介绍的所有6种方法。因此,将所提出的方法与以下内容进行比较:
- 基准不会执行任何过采样,并且会使用原始数据集训练分类器;
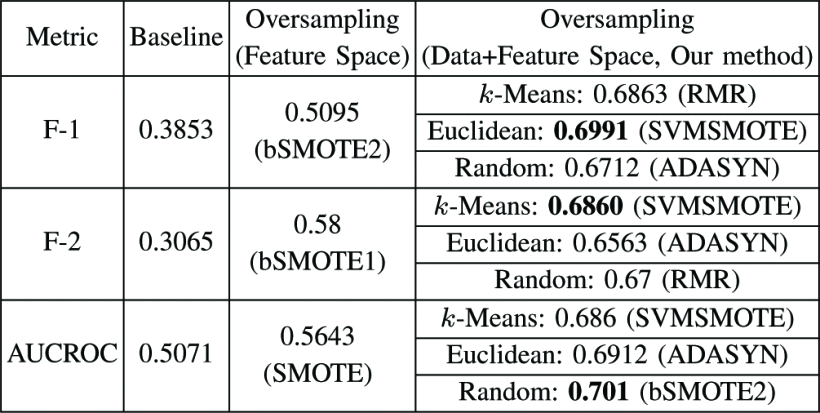
- 过采样(特征空间)执行现有的特征空间过采样方法,并使用增强的数据集训练分类器。我们执行网格搜索以在可用的6个选项中找到最佳的过采样方法。在表III至V中,我们报告了分数以及从网格搜索获得的最佳特征空间过采样方法。
我们使用F-1,F-2和AUCROC分数作为评估性能的主要指标。F-1是精度和召回率的谐波平均值,而F-2则是对phishy类召回率的更大权重。
3.3 实验结果
Phishing URL Hunting Results
通过我们提出的方法可以重新创建一些测试网络钓鱼URL:如表II所示,在实验过程中可以重新创建测试集中的40〜80个网络钓鱼URL 。对于Sorio等人的数据集,我们的方法能够在其测试集中生成100多个未知的网络钓鱼URL。

Phishing URL Detection Results
在表III至VI中,总结了每个数据集的详细分数。除了Sorios等人,所有基线方法的F-2分数均低于0.4。数据集。这意味着未识别出许多网络钓鱼URL,这表示不可靠。所有分类器都偏向多数类。
ebay dataset
PayPal dataset
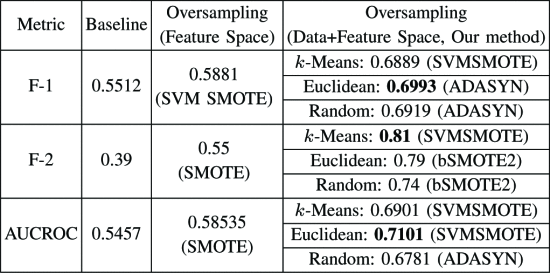
Back of America dataset
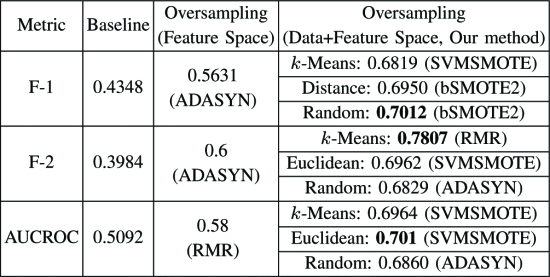
Sorio’s dataset
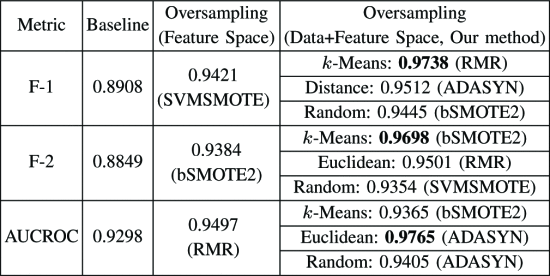
在执行特征空间过采样之后,F1和F2分数在我们的数据集中都稳定在0.5和0.6之间,而在Sorio等人中则稳定在0.93和0.97之间。在某些情况下,它显示出比以前的基准更好的性能(例如,在ebay数据集中从0.3到0.58,在美国银行从0.43到0.56)。这证明了传统的过采样技术能增强分类任务。
最后一栏中提出的方法在所有情况下均显示最佳性能,并且几乎在所有情况下均获得大于0.7的分数。我们的方法在很大程度上优于其他方法:例如,我们的方法显示PayPal数据集的F-2得分为0.81,而其他基线仍然为0.39和0.55(即,相对于两种基线方法分别提高了107%和47%)。不出所料,在几乎所有情况下,基于k -Means或欧几里德距离的代表性URL选择均优于随机代表选择,这支持了代表性选择的重要性。
四、结论
过采样被认为是解决数据集不平衡问题的最佳方法。但是,给定一组URL的现有方法会在特征空间中找到代表URL的向量的加权组合。
在最近提出的称为生成对抗网络的生成模型的启发下,我们提出了一种生成一组更好的合成URL的新颖方法。我们还收集了最近发现的可疑URL。随着攻击者修改其URL生成策略,我们希望确保及时更新数据集。在整个实验过程中,我们观察到模型相对于基线方法产生了显着改善。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!