实现 BloomFilter
本文最后更新于:2022年4月9日 中午
简介
日常开发中,我们常常需要面对这样一个场景,判断一个元素是否存在集合当中,如我的这个需求,判断用户是否为新用户。一般数据量比较少的时候,很好处理,Java和Redis都提供了Set这个数据结构,我们可以直接调用方法来进行判断即可。但是当数据量比较大时,无论是Java亦或者是Redis中的Set都会占据相当一部分内存,影响整体性能。因此,BloomFilter应运而生。BloomFilter可以理解为一个不怎么精确的Set结构,因为可能存在误判。
原理
BloomFilter是一种概率型数据结构,它由一个长度为m的二进制向量(其实就是位数组)和k个哈希函数组成,其特点是插入和查询的效率非常高,但缺点是存在一定的误判率和删除困难。
位数组初始化时各位上都是0,如下所示:
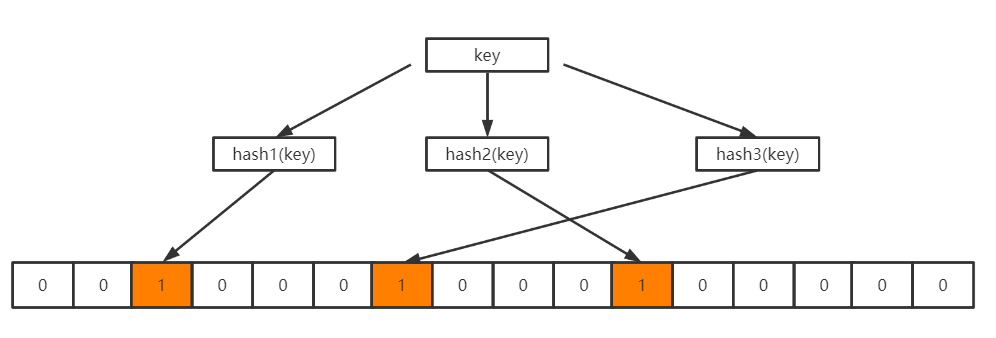
当向BloomFilter中存入一个key时,经过k个哈希函数的计算之后得到k个不同的哈希值,这些哈希值再模以位数组的长度m,得到k个数组中的位置,再将这些位置上的0修改为1,如下所示:
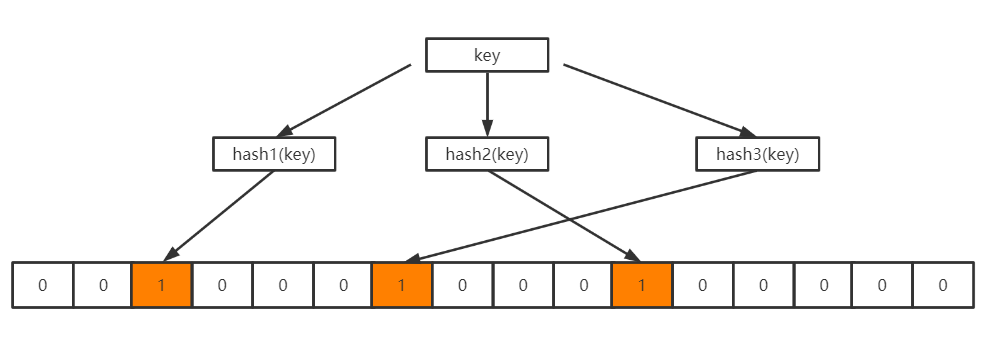
当想要查询这个key是否存在时,也很简单,通过哈希函数和位数组的长度获得key映射在位数组上的不同位置,若是有一个位置上仍是0,那么这个key就一定不存在于这个bloomFilter上。若是不同位置上都是1,则这个key有可能存在于这个BloomFilter中。为什么说是有可能呢?考虑一下下图这个场景。
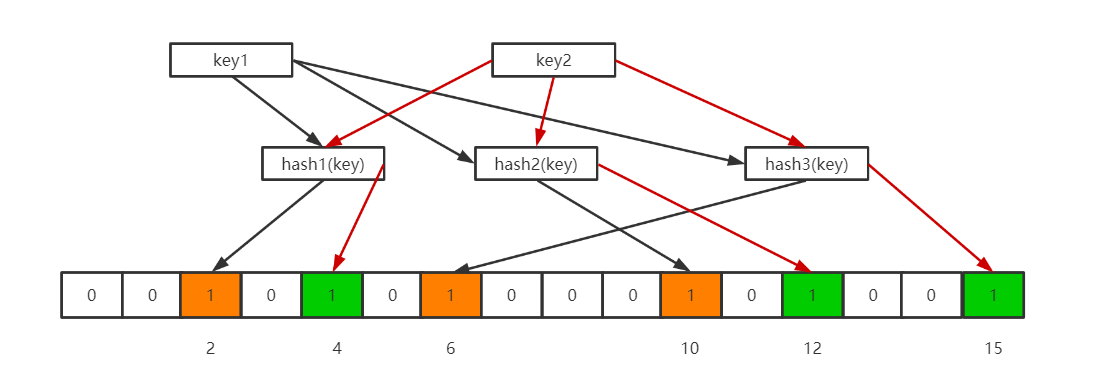
此时有key1、key2两个key在BloomFilter上,导致位数组的2,、4、6、10、12、15位置上都为1。假设现在有一个key3,经过计算之后,其在位数组上的位置分别是2、6、12。这三个位置上都是1,那么这个key3到底在不在BloomFilter里面呢?这个就不得而知了,这也是BoolFilter存在误判的原因。所以才有了那个结论:当我们搜索一个值的时候,若该值经过 k 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中。
一句话就是,不存在就一定不存在,存在也可能是不存在的。
误判率
当位数组长度比较小,且哈希函数比较少时,经过n个key之后,可以预见位数组上大部分都已经是1,这个时候误判率将会非常高,因为你没办法区分位置上的1是由key自身生成的,还是设置其他key导致的。所以,误判率是由哈希函数的个数k、位数组长度m以及key个数n共同决定的,公式如下所示:
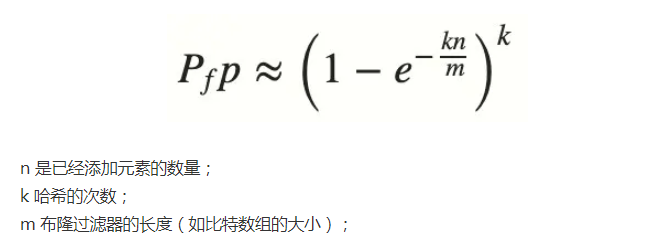
极端情况下,当BloomFilter没有空闲空间的时候,每一次查询都会返回true。这就意味着我们在初始化BloomFilter时要预估好key的个数n和位数组长度m,需要使得m远远大于n。
位数组长度m可以根据预估误判率FFP和预估key的数量计算得到,如下所示:
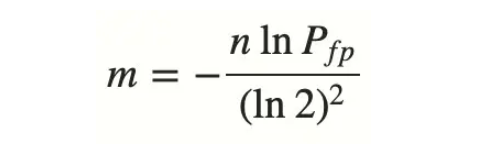
具体的数学推导,可以参考这篇文章。
当位数组长度m确定之后,哈希函数个数k可以依靠下面公式大概估计出来:
1 | |
上面的公式计算起来可能比较麻烦,网上有人提供了一个网址,可以直接刷入相关参数来获得具体的值,有兴趣的话可以自己看一下,布隆计算器。
假如在使用BloomFilter时,位数组长度设置有误,导致最后添加的key数量n大于位数组长度m时,误判率会如何变化。这时候另一个公式派上用场:
1 | |
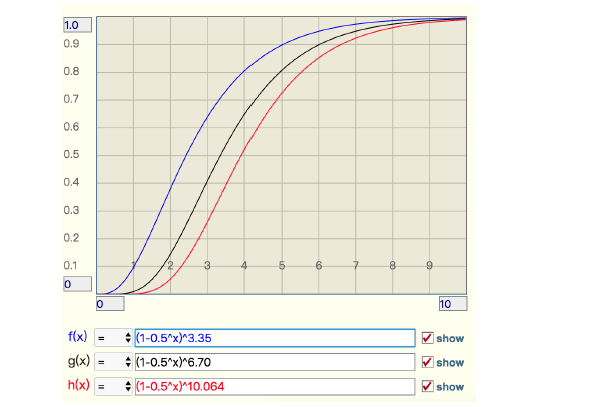
上图出自《Redis深度历险:核心原理和应用实践》中,关于t增大时,误判率的变化。可以发现t增大时,误判率将会增大。
实现
1 | |
应用
在实际工作中,布隆过滤器常见的应用场景如下:
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。 除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
参考:
BloomFilter简介 — 凡尘多遗梦
5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有! — 架构文摘
Implementing a simple, high-performance Bloom filter in C++ — Daan Kolthof
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!