每个开发人员都应该了解的内存管理
本文最后更新于:2024年7月6日 下午
这篇文章是由Zachary Lee撰写的,探讨了程序设计中的一个关键方面:内存管理,特别是对于网页开发者来说,理解内存管理的高层次抽象非常有用。它讲述了栈(stack)和堆(heap)在程序中的作用,以及如何根据数据的大小和生命周期来决定存储位置,同时介绍了不同编程语言如何处理堆内存的管理。
说明:本文摘自 Memory Management Every Developer Should Know @Zachary Lee
What data is put on the stack and what data is put on the heap?
哪些数据放在栈上,哪些数据放在堆上?
This article explores a crucial aspect of programming: memory management. You might have a vague idea about it or often overlook it. We’ll focus on high-level memory management abstractions, which may prove useful if you’re looking to understand memory management from a broader perspective, especially as a web developer.
本文探讨了编程的一个重要方面:内存管理。您可能对此有一个模糊的想法或经常忽视它。我们将重点关注高级内存管理抽象,如果您希望从更广泛的角度了解内存管理,尤其是作为 Web 开发人员,这可能会很有用。
Question 问题
Let me ask you a question first:
我先问你一个问题:
What data is put on the stack and what data is put on the heap?
哪些数据放在栈上,哪些数据放在堆上?
If you are good at languages with automatic memory management such as JavaScript/Python/Java, you might say the following answer:
如果你擅长JavaScript/Python/Java等具有自动内存管理功能的语言,你可能会说出以下答案:
Primitive types are stored on the stack, objects are stored on the heap, closure variables are stored on the heap, and so on.
基本类型存储在栈上,对象存储在堆上,闭包变量存储在堆上,等等。
Is this answer correct? No problem, but this is only the surface, not the essence. So what is the essence?
这个答案正确吗?没问题,但这只是表面,不是本质。那么本质是什么?
Let’s first analyze the stack and heap in the program, and then give the answer.
我们先分析一下程序中的栈和堆,然后给出答案。
Stack 堆
The stack data structure is characterized by first-in, last-out. Because of this feature, it is very suitable for recording the function calls of the program, which is also called the function call stack. Then take a look at the following simple code example:
栈数据结构的特点是先进后出。由于这个特点,非常适合记录程序的函数调用,也称为函数调用堆栈。然后看下面的简单代码示例:
1 | |
Let’s analyze it. First, the code we write will be executed as an “entry”. Please see the following diagram:
我们来分析一下。首先,我们编写的代码将作为“入口”执行。请看下图:
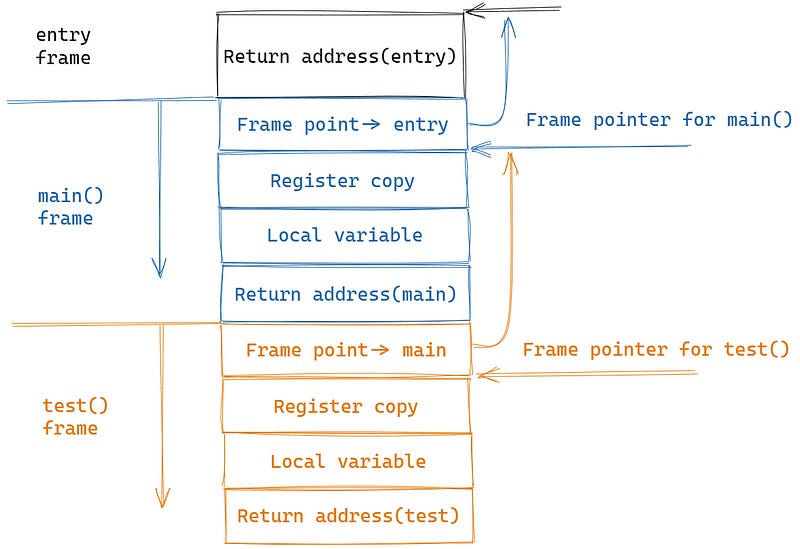
The function call stack grows from top to bottom. In this simple code example, the call flow is entry -> main() -> test().
函数调用堆栈从上到下增长。在这个简单的代码示例中,调用流程是 entry -> main() -> test() 。
Next, whenever a function executes, a contiguous piece of memory is allocated at the top of the stack, which is called a frame.
接下来,每当函数执行时,就会在堆栈顶部分配一块连续的内存,称为帧。
This “frame” stores the context information of the current function’s general-purpose registers and the current function’s local variables.
这个“帧”存储了当前函数的通用寄存器和当前函数的局部变量的上下文信息。
In this example, when main() calls test(), it will temporarily interrupt the current CPU execution process, and store a copy of the main() general-purpose register in the stack. After the test() is executed, the original register context will be restored according to the previous copy, as if nothing had happened.
在此示例中,当 main() 调用 test() 时,它将暂时中断当前 CPU 执行过程,并将 main() 通用寄存器的副本存储在堆栈中。 test()执行后,会根据之前的副本恢复原来的寄存器上下文,就好像什么也没发生过一样。
Cool, that’s the magic of general-purpose registers!
酷,这就是通用寄存器的魔力!
Then, as the function is called layer by layer, the stack will expand layer by layer, and after the call ends, the stack will backtrack layer by layer, and the memory occupied by each frame will be released one by one.
然后,随着函数的一层层调用,栈会一层层扩展,调用结束后栈会一层层回溯,每一帧占用的内存都会被一一释放。
But wait, we seem to be missing something. In usual circumstances, it requires contiguous memory space, which means that the program must know how much memory space the next function needs before calling the next function.
但是等等,我们似乎遗漏了一些东西。通常情况下,它需要连续的内存空间,这意味着程序在调用下一个函数之前必须知道下一个函数需要多少内存空间。
So how does the program know?
那么程序是如何知道的呢?
The answer is that the compiler does it all for us.
答案是编译器为我们完成了这一切。
When compiling code, a function is the smallest compilation unit. Whenever the compiler encounters a function, it knows the space required by the current function to use registers and local variables.
编译代码时,函数是最小的编译单元。每当编译器遇到一个函数时,它就知道当前函数使用寄存器和局部变量所需的空间。
Therefore, data whose size cannot be determined at compile time or whose size can be changed cannot be safely placed on the stack.
因此,无法在编译时确定大小或可以更改大小的数据不能安全地放置在堆栈上。
Heap 堆
As mentioned above, that data cannot be safely placed on the stack, so it is better to put it on the heap, such as the following variable-length array:
上面说过,数据不能安全地放在栈上,所以最好放在堆上,比如下面的变长数组:

When creating an array without specifying its length, the program needs to dynamically allocate memory. For example, in C, this is typically done using the malloc() function. Initially, a certain amount of space is reserved (for instance, space for 4 elements might be reserved in Rust). If the actual usage of the array exceeds this capacity, the program allocates a larger memory block, copies the existing elements into it, adds the new elements, and then frees the old memory. This process allows the array to dynamically resize as needed.
当创建数组而不指定其长度时,程序需要动态分配内存。例如,在 C 中,这通常是使用 malloc() 函数完成的。最初,会保留一定量的空间(例如,Rust 中可能会保留 4 个元素的空间)。如果数组的实际使用量超过了这个容量,程序会分配一个更大的内存块,将现有元素复制到其中,添加新元素,然后释放旧内存。此过程允许数组根据需要动态调整大小。
The process of requesting system calls and finding new memory and then copying it one by one is very inefficient.
请求系统调用并找到新的内存然后一一复制的过程是非常低效的。
So the best practice here is to reserve the space that the array really needs in advance.
所以这里最好的做法是提前预留数组真正需要的空间。
In addition, the memory that needs to be referenced across the stack also needs to be placed on the heap, which is well understood because once a stack frame is reclaimed, its internal local variables will also be reclaimed, so sharing data in different call stacks can only use the heap.
另外,需要跨栈引用的内存也需要放在堆上,这很好理解,因为一旦一个栈帧被回收,其内部的局部变量也会被回收,所以在不同的调用栈中共享数据只能使用堆。
But this brings up a new question, when will the memory occupied on the heap be released?
但这又带来了一个新的问题,堆上占用的内存什么时候会被释放呢?
Garbage collection 垃圾收集
The major programming languages have given their answers:
各大编程语言都给出了答案:
The early C language left all this to developers to manage manually, which is an edge for experienced programmers because of the finer control over the program’s memory. But for those who are beginners, it is important to keep in mind those best practices for memory management. But unlike machines, there can always be some oversights, which can lead to memory safety issues, resulting in programs running slowly or crashing outright.
早期的 C 语言将所有这些都留给开发人员手动管理,这对于经验丰富的程序员来说是一个优势,因为可以更好地控制程序的内存。但对于初学者来说,记住这些内存管理的最佳实践很重要。但与机器不同的是,总会存在一些疏忽,这可能会导致内存安全问题,导致程序运行缓慢或彻底崩溃。
A series of programming languages represented by Java use Tracing GC (Tracing Garbage Collection) to automatically manage heap memory. This approach takes the burden off the developer by automatically managing memory by periodically marking objects that are no longer referenced and then cleaning them up. But it needs to perform extra logic when marking and freeing memory, which causes STW (Stop The World), like the program gets stuck, and those times are also indeterminate. Therefore, if you want to develop some systems with high real-time requirements, GC-like languages are generally not used.
以Java为代表的一系列编程语言都使用Tracing GC(Tracing Garbage Collection)来自动管理堆内存。这种方法通过定期标记不再引用的对象然后清理它们来自动管理内存,从而减轻了开发人员的负担。但是在标记和释放内存时需要执行额外的逻辑,这会导致STW(Stop The World),就像程序卡住一样,而且这些时间也是不确定的。因此,如果要开发一些实时性要求较高的系统,一般不会使用类似GC的语言。
Apple’s Objective-C and Swift use ARC (Automatic Reference Counting), which inserts retain/release statements for each function at compile time to automatically maintain the reference count of objects on the heap. When an object’s reference count is 0, the release statement can release the object. But it adds a lot of extra code to handle reference counting, making it less efficient and less throughput than GC.
Apple的Objective-C和Swift使用ARC(自动引用计数),它在编译时为每个函数插入retain/release语句,以自动维护堆上对象的引用计数。当对象的引用计数为0时,release语句可以释放该对象。但它添加了很多额外的代码来处理引用计数,使其效率低于 GC,吞吐量也较低。
Rust uses the ownership mechanism, which binds the life cycle of the data on the heap and the life cycle of the stack frame by default. Once the stack frame is destroyed, the data on the heap will also be discarded, and the occupied memory will be released. And Rust also provides APIs for developers to change this default behavior or customize the behavior on release.
Rust采用了所有权机制,默认将堆上数据的生命周期和栈帧的生命周期绑定在一起。一旦栈帧被销毁,堆上的数据也会被丢弃,占用的内存也会被释放。 Rust 还为开发人员提供 API 来更改此默认行为或自定义发布时的行为。
Conclusion 结论
The data stored on the stack is static, of fixed size, and a fixed life cycle, and cannot be referenced across the stack.
栈上存储的数据是静态的,大小固定,生命周期固定,不能跨栈引用。
The data stored on the heap is dynamic, not fixed size, not fixed life cycle, and can be referenced across stacks.
堆上存储的数据是动态的、不固定大小、不固定生命周期、可以跨栈引用。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!